注意:这是一篇从旧博客恢复的文章。
有一本“反人类”的书,叫做《短码之美》(慎读!)。之前看到上面用字符串作为cmp函数传入sort函数的方法,感觉很神奇,但没理解。现在学过汇编之后再去看它,终于有点理解了。
先上一段C++代码:
#include<iostream>
#include<algorithm>
using namespace std;
int main()
{
int a[]={23,5,1,1234,3};
sort(a,a+5,(bool(*)(int,int))"\x55\x89\xe5\x8b\x45\x08\x3b\x45\x0c\x0f\x9f\xc0\x5d\xc3");
for (int i=0;i<5;i++)
cout<<a[i]<<' ';
return 0;
}
其中,我们用一个十六进制串(当然也就是二进制串)代替了cmp函数,由于const char *类型与函数指针类型都属于指针,所以可以直接作参数传入。但需要强制转换成函数指针类型这样才能编译通过。bool(*)(int,int)就是个含有两个int参数,返回一个bool类型的函数指针类型。
如果用C编译,则代码更短(但cmp函数更长一些),因为C语言对头文件及变量类型的要求不是很严格。代码如下:
int main()
{
int a[]={23,5,1,1234,3};
qsort(a,5,sizeof(int),"\x55\x89\xe5\x8b\x45\x0c\x8b\x10\x8b\x45\x08\x8b\x00\x89\xd1\x29\xc1\x89\xc8\x5d\xc3");
int i;
for (i=0;i<5;i++)
printf("%d ",a[i]);
return 0;
}
C语言没有sort,因此使用qsort,cmp函数也使用qsort所需的cmp函数进行重写。
究竟为何这样写就可以呢?
其实就是把cmp函数对应的机器码直接写入内存。
怎么得到机器码呢?
可以这样做。在一个单独的文件里写这个函数,例如(C++版):
bool cmp(int a,int b)
{
return a>b;
}
C语言版qsort的cmp函数(但要注意这并非标准的写法,标准的写法传入的是const void *类型,使用时要强制转换成所需类型):
int cmp(int *a,int *b)
{
return *b-*a;
}
之后编译成.o文件,再使用GCC的objdump进行反汇编,执行过程如下:
C:\Users\fz\Desktop>C:\MyProgram\CodeBlocks\MinGW\bin\g++ -c temp.cpp
C:\Users\fz\Desktop>C:\MyProgram\CodeBlocks\MinGW\bin\objdump.exe -d temp.o
temp.o: file format pe-i386
Disassembly of section .text:
00000000 <__Z3cmpii>:
0: 55 push %ebp
1: 89 e5 mov %esp,%ebp
3: 8b 45 08 mov 0x8(%ebp),%eax
6: 3b 45 0c cmp 0xc(%ebp),%eax
9: 0f 9f c0 setg %al
c: 5d pop %ebp
d: c3 ret
e: 90 nop
f: 90 nop
那些十六进制数便是机器指令了。指令到nop之前结束。
之后将其写入字符串中,把字符串的首地址当做函数指针传入即可。
但是为什么这样就可以呢?
我们传入一个字符串,字符串是存到内存中的,也就是说,我们在内存中写入了机器指令,并把这些指令的地址给了程序。
其实在这里存在一定的凑巧成分。用类似的方法在linux上测试就不成功。原因在于两个操作系统以及GCC存在差别。
借用书上的原话解释一下这个问题:
“通常在x86系统上编译的C语言代码,在函数调用时基于cdecl调用规则。cdecl会将传递的参数按照从右向左的顺序依次推入栈中。另外,int类型的返回值会存放在x86寄存器的EAX寄存器中。在前面的汇编语言代码的例子中,并没有注意这样的规则,而是简单地将机器语言的数据反编译成了汇编语言代码。所以充分理解调用规则后,只要正确地写出调用栈,并把返回值放在EAX寄存器的汇编语言代码就可以了。”
因此我们还可以进一步简化代码,只需按照汇编语言的规则写出相应的机器语言代码即可。例如省略push和pop操作,直接进行寄存器相减。在此不再深入讨论。
但是像上面那样用\x表示十六进制数的方法实在太臃肿了。我们知道一个ASCII字符(一个字节)可以表示两个十六进制数。那么我们可以利用这一点。
但是有个问题,不是所有的字符都能用实际的字符表示出来的。所以考虑使用混合表示法,例如把"\x55\x89\xe5\x8b\x45\x08\x3b\x45\x0c\x0f\x9f\xc0\x5d\xc3"改写成"U\x89\xe5\x8b\x45\x08;E\x0c\x0f\x9f\xc0]\xc3"。其实还是没能解决什么问题,而且有些字符不能改,例如某个\x45其实可以改成E的,但是改成E之后会跟前面的\x8b误认为是一起的成为十六进制数8BE。
书上使用了直接对源文件进行二进制修改的方法。
使用UltraEdit打开cpp文件,并在相应位置修改:
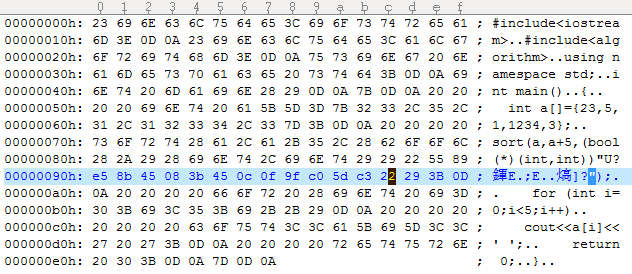
然后直接编译即可,虽然可能显示乱码,但是编译是没问题的。
另外需要注意一下源文件的编码格式,要使用ANSI编码。
欢迎留言